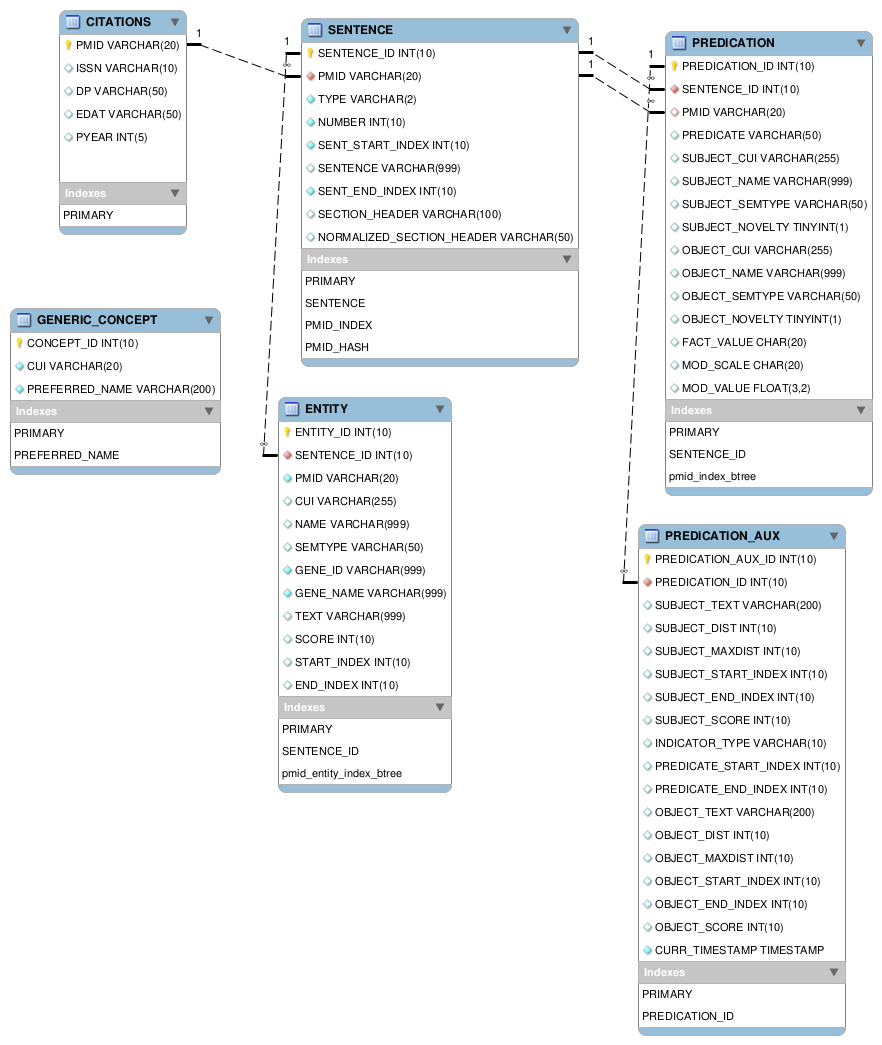
In this page, we provide detailed information about the SemMedDB schema. The database tables, their fields, and the relationships between the tables are explained. Recently we changed the database schema as shown below and applied it in building the latest databases, semmedVER30 and semmedVER30_A. For the previous version of the database schema, click here. Examples for each table are provided below.
TABLES:
Name: CITATIONS table
This table contains relevant metadata for each PubMed citation and has the following data fields:
- PMID: PubMed identifier of the citation
- ISSN: ISSN identifier of the journal or the proceedings where the article was published
- DP: Publication date for the citation
- EDAT: The date when the citation was added to PubMed
- PYEAR: Completion date for the citation
| PMID |
ISSN |
DP |
EDAT |
PYEAR |
| 19851774 |
1432-203X |
2009 Dec |
2010 01 21 |
2009 |
Name: GENERIC_CONCEPT table
This table contains the UMLS Metathesaurus concepts that are considered too generic based upon the 2006AA release. Concepts that are not stored in this table are considered novel. This table is used to populate the SUBJECT_NOVELTY and OBJECT_NOVELTY columns in the PREDICATION table defined below. Data fields in this table are as follows:
- CONCEPT_ID: Auto generated primary key for each concept
- CUI: The Concept Unique Identifier (CUI)
- PREFERRED_NAME: The preferred name of the concept
1956C0699748Pathogenesis
| CONCEPT_ID |
CUI |
PREFERRED_NAME |
Name: SENTENCE table
This table contains information about individual sentences from PubMed citations and includes the following data fields:
- SENTENCE_ID: Auto-generated primary key for each sentence
- PMID: The PubMed identifier of the citation to which the sentence belongs
- TYPE: 'ti' for the title of the citation, 'ab' for the abstract
- NUMBER: The location of the sentence within the title or abstract
- SENT_START_INDEX: The character position within the text of the MEDLINE citation of the first character of the sentence NEW
- SENT_END_INDEX: The character position within the text of the MEDLINE citation of the last character of the sentence NEW
- SECTION_HEADER: Section header name of structured abstract (from Version 3.1)
- NORMALIZED_SECTION_HEADER: Normalized section header name of structured abstract (from Version 3.1)
- SENTENCE: The actual string or text of the sentence
Name: PREDICATION table
Each record in this table identifies a unique predication. The data fields are as follows:
- PREDICATION_ID: Auto-generated primary key for each unique predication
- SENTENCE_ID: Foreign key to the SENTENCE table
- PMID: The PubMed identifier of the citation to which the predication belongs
- PREDICATE: The string representation of each predicate (for example TREATS, PROCESS_OF)
- SUBJECT_CUI: The CUI of the subject of the predication
- SUBJECT_NAME: The preferred name of the subject of the predication
- SUBJECT_SEMTYPE: The semantic type of the subject of the predication
- SUBJECT_NOVELTY: The novelty of the subject of the predication
- OBJECT_CUI: The CUI of the object of the predication
- OBJECT_NAME: The preferred name of the object of the predication
- OBJECT_SEMTYPE: The semantic type of the object of the predication
- OBJECT_NOVELTY: The novelty of the object of the predication
Name: PREDICATION_AUX table
This table has auxiliary information for the predications recorded in the PREDICATION table. There is a 1-to-1 relation between the PREDICATION and the PREDICATION_AUX table. For a full list of indicator types, see the Appendix in [2]. The PREDICATION_AUX table includes the following data fields:
- PREDICATION_AUX_ID: Auto-generated primary key for the auxiliary information of each unique predication
- PREDICATION_ID: Foreign key to the PREDICATION table
The rest of the fields in PREDICATION_AUX table provide mention-level information for the elements of the predication.
- SUBJECT_TEXT: Text that maps to the subject
- SUBJECT_DIST: The distance of the subject mention (counted in noun phrases) from the predicate mention (0 for certain indicator types, such as NOM)
- SUBJECT_MAXDIST: The number of potential arguments (in noun phrases) from the predicate mention in the direction of the subject mention (0 for certain indicator types, such as NOM)
- SUBJECT_START_INDEX: The first character position (in document) of the text denoting the subject entity
- SUBJECT_END_INDEX: The last character position (in document) of the text denoting the subject entity
- SUBJECT_SCORE: The confidence score of the mapping between the subject string and the subject concept
- INDICATOR_TYPE: The part of speech of the predicate, such as VERB for verbal predicates and NOM for nominalizations and other argument-taking nouns. For a full list of indicator types, see the Appendix in [2]
- PREDICATE_START_INDEX: The first character position (in document) of the text denoting the relation
- PREDICATE_END_INDEX: The last character position (in document) of the text denoting the relation
- OBJECT_*: The fields representing information about the object, in the same way the SUBJECT_* fields do for the subject
- CURR_TIMESTAMP: The timestamp for the record
Name: COREFERENCE table
This table has coreference information generated by SemRep with Anaphora (option -A). It includes the following data fields:
- COREFERENCE_ID: Auto-generated primary key for each unique coreference
- PMID: The PubMed identifier of the citation to which the coreference belongs
- ANA_CUI: The CUI of the anaphor element of the coreference
- ANA_NAME: The preferred name of the anaphor element of the coreference
- ANA_SEMTYPE: The semantic type of the anaphor element of the coreference
- ANA_TEXT: The text that maps to the antedecent
- ANA_SENTENCE_ID: The foreign key to SENTENCE of the anaphor element of the coreference
- ANA_START_INDEX: The first character position (in document) of the text denoting the anaphor
- ANA_END_INDEX: The last character position (in document) of the text denoting the anaphor
- ANA_SCORE: The confidence score of the mapping between the anaphor text and the anaphor concept
- ANT_CUI: The CUI of the antecedent element of the coreference
- ANT_NAME: The preferred name of the antedecent element of the coreference
- ANT_SEMTYPE: The semantic type of the antedecent element of the coreference
- ANT_TEXT: The text that maps to the antedecent
- ANT_SENTENCE_ID: The foreign key to SENTENCE of the antedecent element of the coreference
- ANT_START_INDEX: The first character position (in document) of the text denoting the antedecent
- ANT_END_INDEX: The last character position (in document) of the text denoting the antedecent
- ANT_SCORE: The confidence score of the mapping between the antedecent text and the anaphor concept
- CURR_TIMESTAMP: The timestamp for the record
Name: ENTITY table
This table contains entity information whose data come from ENTITY output generated using full fielded output. It includes the following data fields:
- ENTITY_ID: Auto-generated primary key for each unique entity
- SENTENCE_ID: The foreign key to SENTENCE table
- CUI: The CUI of the entity
- NAME: The preferred name of the entity
- TYPE: The semantic type of the entity
- GENE_ID: The EntrezGene ID of the entity
- GENE_NAME: The EntrezGene name of the entity
- TEXT: The text in the utterance that maps to the entity
- START_INDEX: The first character position (in document) of the text denoting the entity
- END_INDEX: The last character position (in document) of the text denoting the entity
- SCORE: The confidence score
The entity-relationship diagram of SemMedDB version 4.2 or higher version is shown below graphically:
NEW