AREAS OF INTEREST
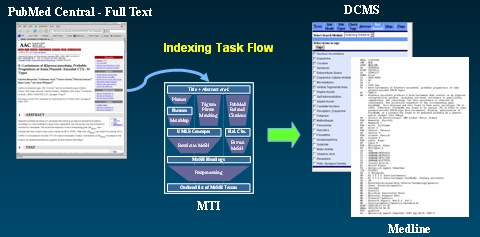
Another major area of planned research recognizes the fact that our current indexing methods rely only on titles and abstracts, while human indexers base their analysis on the full text of an article. This restriction causes the computer-generated terms to suffer recall errors in comparison to the humanly assigned document descriptors. Given the increasing availability of machine readable full text, we have an ongoing full text processing effort.
Our initial efforts investigated the full text articles and their structure since optimal results are likely to be achieved by addressing those sections of a full text article which concentrate on the main points of the article. Next we built models of the articles using subsets of sections and evaluated them to which sections best covered the main points. This work is described in an AMIA paper, Semi-Automatic Indexing of Full Text Biomedical Articles, AMIA 2005 (PDF: 100kb). To review AMIA talk for this paper, please follow this link: AMIA Talk on Semi-Automatic Indexing of Full Text Biomedical Articles paper. A more detailed description of this research can also be found in the project report: MTI for Full Text, March 2005 (PDF: 105kb).
Subsequent research looked into several approaches to tune MTI parameters and processing to take advantage of the full text. Most of those approaches did not make significant improvements in MTI's performance on full text. That work is reported in MTI for Full Text - Phase 2, May 2005 (PDF: 34kb).
Because the subtler attempts to improve these initial full text results were not successful, we have initiated a more elaborate attempt to identify the important text within the article. We are using automatic summarization techniques to select the important text before MTI processing. We are using the approach of Yeh, Ke, Yang, Meng. It combines Latent Semantic Analysis and Salton's Text Relationship Map to provide a ranked list of sentences from the article. We will use this technique to summarize the text in our current best-performing model. We are also enriching our document (article) representation by including MetaMap identified concepts with the usual bag of words. That work is reported in Identification of Important Text in Full Text Articles Using Summarization, July 5, 2006 (PDF: 98kb).
Additionally, insights from human indexer practices provided guidance for the automatic methods being developed. For example, in a preliminary study on the effect of key sentences on MTI results, we used the observations from an expert indexer that the last (and sometimes the first) sentence of the Introduction of a full journal article often supplies crucial information about how to index the article, and that the subsection headers in the Results section often include important topics.