LexAccess Introduction
I. What is LexAccessLexAccess is used to retrieve lexical records from the Lexicon. This tool is developed in pure Java to replace lf, lcat, and llk. Currently, the inputs, outputs, and options for this tool are:
II. How does LexAccess work?
The SPECIALIST lexicon has been developed to provide the lexical information needed for the SPECIALIST Natural Language Processing System. It is intended to be a general English lexicon that includes many biomedical terms. Coverage includes both commonly occurring English words and biomedical vocabulary. The lexicon entry for each word or term records the syntactic, morphological, and orthographic information needed by the SPECIALIST natural language processing system.
Technically speaking, a lexical record is the record for all above information for a term (entry). The lexicon is the data set contains all lexical records. All these lexical records are store in a database and can be retrieved by this tool, LexAccess. The conceptual diagram of LexAccess is shown as below:
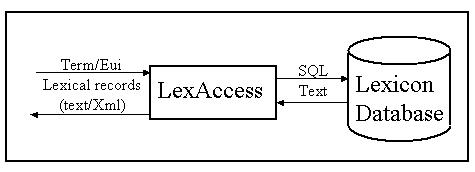
As shown on above, the LexAccess system retrieve lexical records according to the input query (a term or EUI). The retrieved lexical records are in text format. LexAccess system may transfer this text format into Xml format and then display to users. Please refer to the algorithm page for details.