Remove parenthetic plural forms: (s), (es), and (ies)
I. Introduction
There are terms include (s), (es), and (ies) to represent plural form of noun. This becomes a very challenge issue for normalization due to various ways of representation. This study is try to normalize (s), (es), and (ies) for all terms in Metathesaurus by removing them or replacing them with space.
II. Problem Definition
In regular English, we could normalize terms with plural forms of (s), (es), (ies) by removing them. For example:
| Original term | Normalized term |
|---|---|
| Abuse, drug(s), heroin | Abuse, drug, heroin |
| Abdomen CT Adrenal Mass(es) Bilateral | Abdomen CT Adrenal Mass Bilateral |
| Donor pneumonectomy(ies) with preparation and maintenance of allograft (cadaver) | Donor pneumonectomy with preparation and maintenance of allograft (cadaver) |
In our research, all (es) and (ies) in English terms should be removed without any exceptions. However, patterns of (s) appear in chemical, protein, and other expressions do not mean plural forms. In other words, (s) should not be removed in such cases. For example:
In addition, there are some cases that (s) should be replaced with a space instead of removed. For example:
| Original term | Normalized term |
|---|---|
| [X]O spontn disrptn/lig(s)knee | [X]O spontn disrptn/lig knee |
| O spontn disrptn/lig(s)knee | O spontn disrptn/lig knee |
III. Governing Patterns
Fortunately, there are certain patterns we can govern and derived. First of all, the patterns of (s) and (es) we are dealing with are the plural forms of nouns. In other words, the word before this (s) pattern should be a noun. Thus, if we observe the word (characters) in front of (s), there are certain rules we can derived. Table below shows derived rules from above examples:
| Sample term | Pattern in front of (s) | Distance |
|---|---|---|
| 1-N-(s)-4-amino-2-hydroxybutyryl-3'4'-deoxyneamine | punctuation - | 1 |
| 9(s)-erythromycylamine | arabic number 9 | 1 |
| anatoxin-b(s) | punctuation - | 2 |
| Ap(s)pCHClpp(s)A |
| 1 |
| Bacillus phage rho11(s) | arabic number 11 | 1 |
| Cbz-AAPhepsi((s)-CH(OH)CH2)GlyVV-OMe | punctuation ( | 1 |
| EAV G(s) glycoprotein |
| 2 |
| G(s), alpha Subunit | size of front word G <= 2 | n/A |
| Histone H1(s) |
| 1 |
| J(s)(b) ANTIBODY | size of front word J <= 2 | n/A |
| N(alpha)-benzoylarginineamide monohydrochloride, (s)-isomer |
| 1 |
| natoxin-a(s) | punctuation - | 2 |
| Salmonella II 6,7:(g),m,(s),t:1,5 | punctuation , | 1 |
| (s)-(+)-citreofuran | size of front word <= 2 | n/A |
| su(s) protein, Drosophila | size of front word su <= 2 | n/A |
| XLalpha(s) protein | greek letters alpha | 1 |
As for the issue of remove (s) or replace (s) with a space, it is determined by the character following (s). If there is a word follows (s), then it should be replaced by a space. If not, it can be simply removed. Legal English word usually starts with a letter. Thus following rules is derived for cases where we replace (s) with space (" "):
| Sample term | Character after (s) |
|---|---|
| [X]O spontn disrptn/lig(s)knee | k |
IV. Wild Card Set
Let define some wild card character set before we solve the problem:
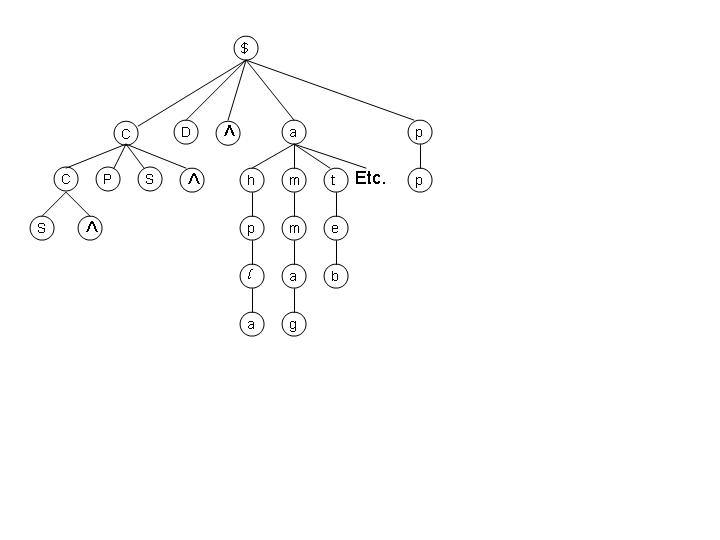
V. Rules Representation
| Rules | Examples |
|---|---|
| D$ | 9(s)-erythromycylamine |
| P$ | Salmonella II 6,7:(g),m,(s),t:1,5 |
| ^$ | (s)-(+)-citreofuran |
| PC$ | N(alpha)-benzoylarginineamide monohydrochloride, (s)-isomer |
| SC$ | EAV G(s) glycoprotein |
| ^C$ | J(s)(b) ANTIBODY |
| SCC$ | Histone H1(s) |
| ^CC$ | su(s) protein, Drosophila |
| pp$ | Ap(s)pCHClpp(s)A |
| alpha$ | XLalpha(s) protein |
| beta$ | |
| gamma$ | |
| delta$ | |
| epsilon$ | |
| zeta$ | |
| eta$ | |
| theta$ | |
| iota$ | |
| kappa$ | |
| lamda$ | |
| mu$ | |
| nu$ | |
| xi$ | |
| omikron$ | |
| pi$ | |
| rho$ | |
| sigma$ | |
| tau$ | |
| upsilon$ | |
| phi$ | |
| chi$ | |
| psi$ | |
| omega$ |
Please notes that rule S$ is not used even it is good for example of
V. Algorithm
Below is the algorithm:
VI. Reversed trie of rules