Derivations - Prefix
I. What are prefix derivations
A prefix is placed at the beginning of a base word to form another word.
Usually, it changes meaning, but rarely change part of speech (en & be)
II. Prefix list
We collected the most common prefixes for derivations from the following sources:
The
derivational prefix list
in current Lexical Tools includes 149 unique prefixes and is subjected to be updated annually.
According to the Merriam-webster.com, a word element that is always and only used as a prefix or suffix, gets called a prefix or suffix. Otherwise, they are combining forms. Both prefixes and combining forms are included in our prefix list.
III. Prefix derivation pairs in LEXICON
All base forms are retrieved from inflectional variants list with inflection is base. These base forms include citations and spelling variants. Prefix derivation pairs are then are retrieved by computer programs if a both "prefix + base" and "base" exists. In lvg.2012, there are 114,902 prefix derivation pairs found in LEXICON for the 142 prefixes. Three type of prefix derivation pairs are found in this program as shown in the following example:
Three types of prefix derivation pair:
prefix: non
nonsignificant|significant
non-significant|significant
non significant|significant
IV. Processes
${DERIVATIONS}/Prefix/data/${YEAR}/dataOrg/inflVars.data
The latest inflVars.data from lexicon.${YEAR}
${DERIVATIONS}/Prefix/data/${YEAR}/dataOrg/prefixList.data
The list of all prefix word. The format is:
| prefix | meaning | examples | status |
${DERIVATIONS}/Prefix/data/${YEAR}/dataOrg/prefix.tag.txt
A manual tag file for prefix derivation. The baseline of this file is the previous year tag file. The tagged file of prefix.tbd.data is then added. The format of this file is:
| prefix | prefix+base | category-1 | EUI-1 | base | category-2 | EUI-2 | tag |
${DERIVATIONS}/Prefix/data/${YEAR}/dataOrg/prefix.new.data
The list of all new prefix pairs from "prefix.tag.txt" that are from new lexRecords. This file is used to validate the program and results. The format is:
| prefix | prefix+base | category-1 | EUI-1 | base | category-2 | EUI-2 | tag |
${DERIVATIONS}/Prefix/data/${YEAR}/dataOrg/LEXICON
shell>cd ${DERIVATIONS}/Prefix/bin
shell>GetPrefixD ${YEAR}
10
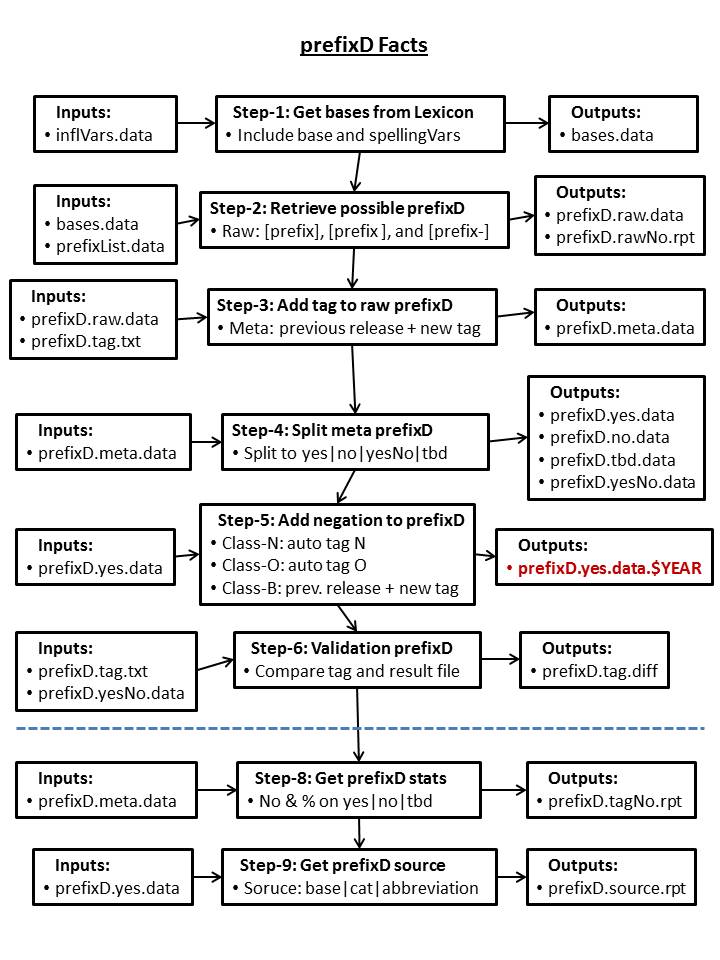
V. Program Details (GetPrefixD)
| base | category | inflection (1) | EUI |
prefix+base and base exists in LEXICON:
| prefix | prefix+base | category-1 | EUI-1 | base | category-2 | EUI-2 |
Please note that not all prefix derivation pairs retrieved from LEXICON (step 2) are valid derivation pairs. We define an eight fields (pipe separated) format for tagging the prefix derivation pairs to validate derivational variants:
| prefix | prefix+base | category-1 | EUI-1 | base | category-2 | EUI-2 |
Examples
an|ana|adv|E0008740|a|noun|E0598106|no an|anaplastic|adj|aplastic|adj|no ana|anabiotic|adj|E0008744|biotic|adj|E0013104|no
The first line is not a valid derivational pair because "ana" and "a" are obviously not derivations. The second line is not a valid derivational pair ("anaplastic" and "aplastic"). The correct one should be:
ana|anaplastic|adj|E0008830|plastic|adj|E0048247|yes
The third line is not a valid derivational pair because "anabiotic" is derived from "anabiosis".
In order to have a high accuracy of derivations, we have experienced domain experts (linguists) to valid all retrieved prefix derivation pairs from LEXICON.
| prefix | prefix+base | category-1 | EUI-1 | base | category-2 | EUI-2 | tag |
| prefix | prefix+base | category-1 | EUI-1 | base | category-2 | EUI-2 | tag |
| prefix+base | category-1 | EUI-1 | base | category-2 | EUI-2 |
| prefix | prefix+base | category-1 | EUI-1 | base | category-2 | EUI-2 | tag |
| prefix+base | category-1 | EUI-1 | base | category-2 | EUI-2 | negation tag |
prefix+base and base exists in LEXICON