SD-Rules Optimization Results
I. The final set
As the result,
we concluded case 2.3.4.5.1 is the final optimized set of SD-Rules in the corpus of Lexicon 2013 to include 73 (out of 96) SD-rules to reach:
This set of SD-rules is expected to reach the same system performance when it is applied to other English corpora under the assumption that:
II. The methodology
This approach is used to find the best set of SD-rules from a set of known candidate SD-rules.
Theoretically, a complete set of SD-Rules can be obtained when more SD-rules are evaluated and added. This methodology provides a systematic approach to:
III. The target accuracy rate (95%)
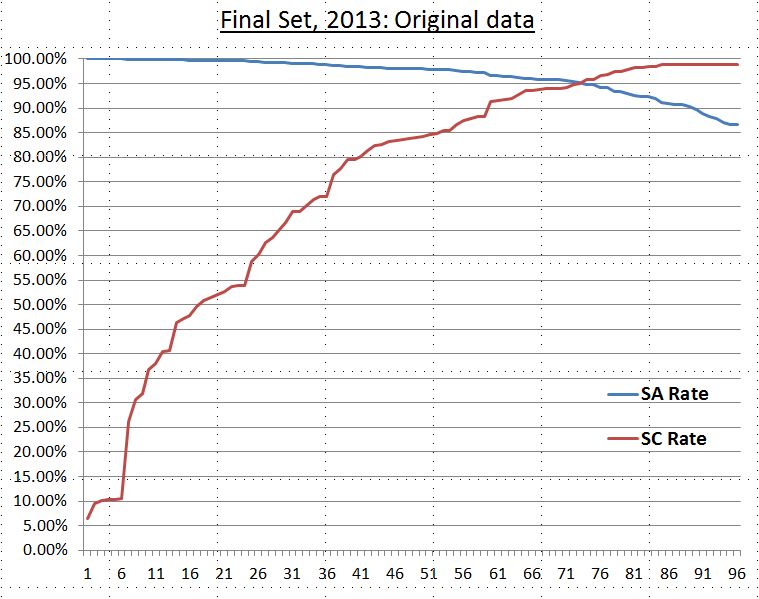
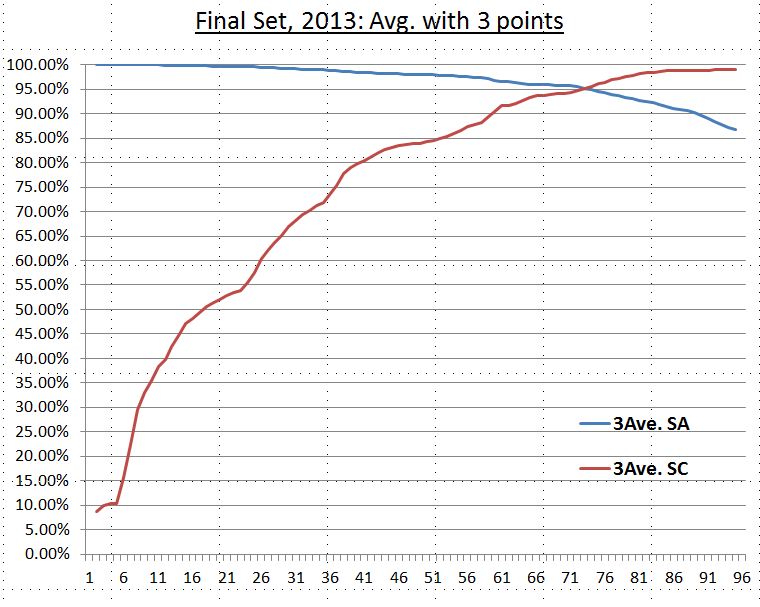
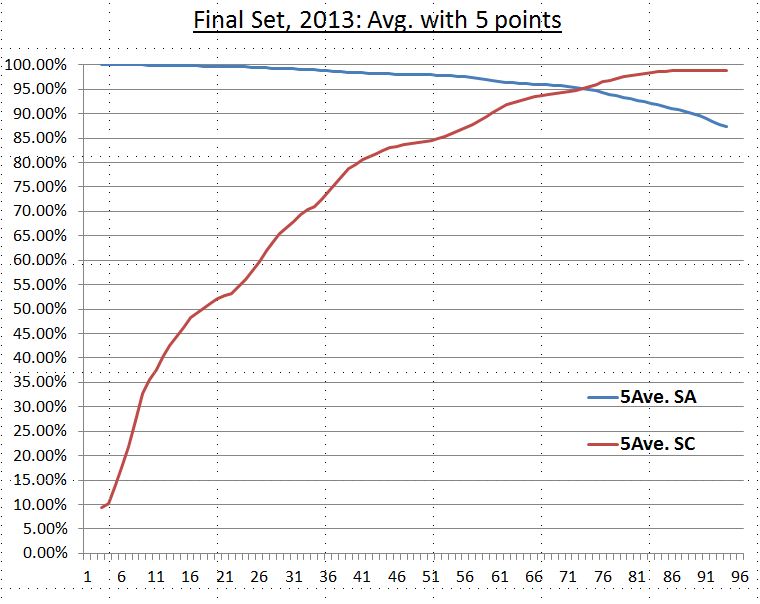
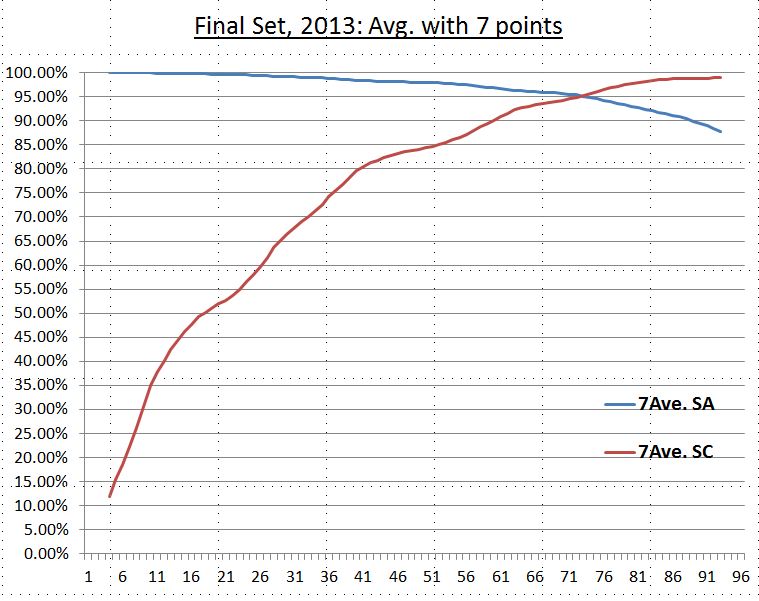
As shown in the previous session, the intersection of curves (optimization) of system accuracy rate and system coverage rate of the final set are at 95%. We also used average values for the window size of 3, 5, 7 rules for these two curves for noise reduction (smoothing algorithm - simple moving average) and find the intersections are all around 95% for all cases (see diagram below). Smoothing this data set allows us to capture the characteristics of this set and leave out noise. Accordingly, our target minimum accuracy rate (95%) is a good choice to obtain the optimized set of SD-rules (close to optmization).