Example - Add SD-Rules Derived from nomD
As discussed in the nominalization derivations session, valid nomD pairs from Lexicon can be generated by computer program automatically. Most of them are valid suffixD. In 2013 release, 14,368 of suffixD are generated from 14,668 valid nomD. A set of program is developed to derive possible SD-rule from these valid SD-pairs and then add to the SD-rule set (from previous session) to increase coverage:
location|noun|locate|verb, generates SD-rule of ion|noun|e|verb by stripping "locat".
shell> GetSdRule 2013
2
nomD
...
shell>GetSdRule 2013
5
2013
$|adj|ness$|noun
...
| Possible SD-rule from nomD | Occurrence | Root | Related | Notes |
|---|---|---|---|---|
| $|adj|ness$|noun | 2489 | Yes | Duplicated | Done - not selected |
| e$|verb|ion$|noun | 1740 | Yes | parents-rule of
| To be evaluated next |
| $|adj|ity$|noun | 1635 | Yes | Duplicated | Done - not selected |
| ility$|noun|le$|adj | 1295 | Yes | parents-rule of
| To be evaluated next |
| ation$|noun|e$|verb | 1164 | Yes | Duplicated | Done - not selected |
| e$|adj|ity$|noun | 604 | Yes | Duplicated | Done - not selected |
| ce$|noun|t$|adj | 522 | Yes | parents-rule of
| To be evaluated next |
| iness$|noun|y$|adj | 501 | Yes | None | Selected |
| $|verb|ment$|noun | 467 | Yes | Duplicated | Done - not selected |
| $|verb|ion$|noun | 381 | Yes | None | Selected |
| cy$|noun|t$|adj | 292 | Yes | parents-rule of
| To be evaluated next |
| ication$|noun|y$|verb | 232 | Yes | Duplicated | Done - not selected |
| $|verb|ation$|noun | 214 | Yes | Duplicated | Done - not selected |
| ed$|adj|ion$|noun | 200 | Yes | None | Selected |
| $|verb|ing$|noun | 194 | Yes | None | Selected |
| e$|adj|ion$|noun | 103 | Yes | None | Not selected due to Low frequency (coverage) |
| ... | ... | ... | ... | Not selected due to low frequency (coverage) |
The iterative results are shown as follows:
| ID | New Candidate Rule | Total Yes | Total Rule No. | Rule No. | A. Rate | Occr. | Yes | No | Tbd | SD-Rule | Status | Source | Notes | Sys A. Rate | Sys C. Rate | Sys. Perf | Notes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.3 (prev. optimized set) | 37,136 | 87 | 65 | 60.66% | 183 | 111 | 72 | 0 | ar$|adj|e$|noun | 2013 | ORG_RULE | SELF | 95.01% | 94.30% | 1.8931 | Baseline | |
| 2.3.1 |
13|99.81%|536|535|1|0|iness$|noun|y$|adj|2013|NOM_D|SELF
| 37,671 = 37,136 + 535 | 88 | 66 | 60.66% | 183 | 111 | 72 | 0 | ar$|adj|e$|noun | 2013 | ORG_RULE | SELF | 95.08% | 94.38% | 1.8946 | Better |
| 2.3.2 |
32|97.70%|651|636|15|0|ed$|adj|ion$|noun|2013|NOM_D|SELF
| 38,307 = 37,671 + 636 | 89 | 67 | 60.66% | 183 | 111 | 72 | 0 | ar$|adj|e$|noun | 2013 | ORG_RULE | SELF | 95.13% | 94.47% | 1.8960 | Better |
| 2.3.3.0 |
46|93.31%|553|516|37|0|$|verb|ion$|noun|2013|NOM_D|PARENT
remove child-rule:
| 38,730 = 38,307 + 516 - 93 | 89 | 67 | 60.66% | 183 | 111 | 72 | 0 | ar$|adj|e$|noun | 2013 | ORG_RULE | SELF | 95.10% | 94.53% | 1.8963 | Better |
| 2.3.3.1 |
1|429|414|15|t$|verb|tion$|noun|96.50%|77.58%
Decomposed from parent-rule:
46|93.31%|553|516|37|0|$|verb|ion$|noun|2013|NOM_D|PARENT
| 38,730 | 89 | 67 | 60.66% | 183 | 111 | 72 | 0 | ar$|adj|e$|noun | 2013 | ORG_RULE | SELF | 95.14% | 94.27% | 1.8941 | Worse |
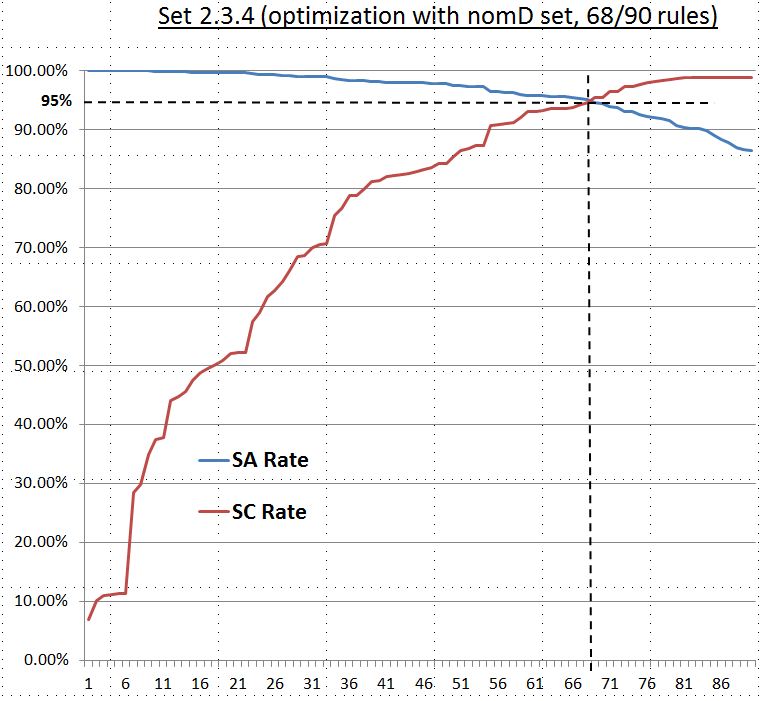
| 2.3.4 |
50|91.57%|510|467|43|0|$|verb|ing$|noun|2013|NOM_D|SELF
| 39,197 = 38,730 + 467 | 90 | 68 | 60.66% | 183 | 111 | 72 | 0 | ar$|adj|e$|noun | 2013 | ORG_RULE | SELF | 95.05% | 94.60% | 1.8965 | Better |
The table above shows the iterative results by adding new rules derived from nomD step by step. Please note that SD-rule ss$|verb|ssion$|noun is removed because it is a child-rule of newly added SD-rule $|verb|ion$|noun for case 2.3.3.
The results show all four selected SD-rules (with the highest frequency from nomD) improve the system performance. Thus, all these four SD-rules are added to the SD-rule set to reach better coverage rate (94.60%) and system performance (1.8965) with accuracy rate of 95.05% to include 68 (out of 90) SD-rule in the optimized set. The diagram below shows the system accuracy and coverage curves of this optimized set.