N-gram Set by Split, Group, Filter, Combine and Sort (SGFCS) Algorithm
This page describes the details of generating n-grams (n = 1-5) from MEDLINE using split and combine algorithm. Due to the n-grams are too big for the Java HashMap limitation, the n-grams retrieving processes can be split (by
I. Basic N-gram Set
n-gram (uniGram, biGram, triGram, fourthGram, fifthGram) from MEDLINE are retrieved from Medline as follows:
II. Split (MEDLINE):
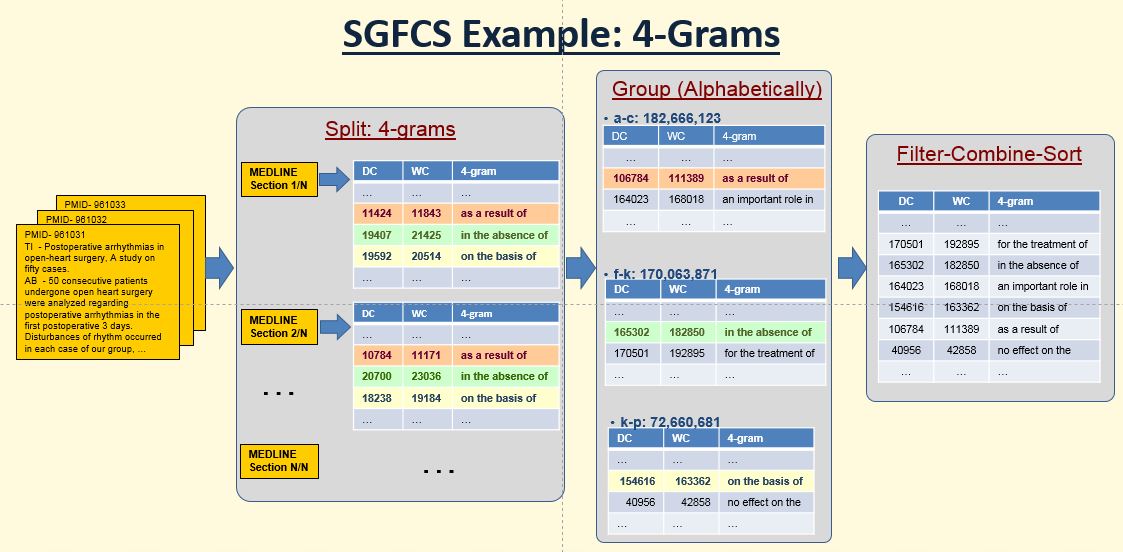
Split the total input MEDLINE files into N portions.
nGram.out.5.heap.50.s20.15
III. Group (by alphabetic order):
Group all split n-gram files with specified range of characters. All n-grams are independent if group (sorted and combined alphabetically) together. The alphabets are in the following order:
| NO, ... 0-9, ... >, ?, @ | A, B, C, ..., X, Y, Z | [, \, ], ^, _, ` | a, b, c, ..., x, y, z | {, |, }, ... NO |
nGram.out.5.heap.50.s20.g05.b-d
IV. Filter (by WC) Combine, then Sort:
Combine and filter out n-grams by WC (which take most portion in higher grams), then sort them by WC, DC and alphabetic order.
V. Exmaple: