Precision for New LMW Candidates from (ACR) Model
I. Introduction
The results from matchers generate LMWs (LexMultiWords) candidates list. This list is sent to linguists to add to Lexicon. An algorithm has been developed to calculate the precision (= valid no/candidates no = retrieved-relevant/retrieved) automatically in this process.
II. Format and Tag
Ideally, no tag is needed because tag can be retrieved from Lexicon. However, we would like to have linguists manually add tag to the LMW candidates as follows to ensure the precision. For example, if linguists forget to tag a candidate and thus it will be considered as invalid MW without manully tagging. With manual tagging, any missed tag can be identify.
| LMW candidate* | Tag |
|---|
Three types of tag are automatically tagged as follows. The algorithm check valid first, then invalid. TBD are other than above two conditions. Filter.Lexicon are used for checking, thus including exact match, exact match after lowercase, match after removing lead-end punctuation, etc..
| Tag | Description | Notes | |||
|---|---|---|---|---|---|
| yes y | known valid LMW from Lexicon |
| |||
| no n | known invalid LMW from previous tag |
| |||
| tbd | To be done (untagged candidates) |
| |||
| o | not a valid acronym expansion (invalid MW) | legency tag, not used| e | a valid expansion that exist in Lexicon (valid MW) | legency tag, not used | |
The tagging results are used to update the invalidMw file. The following checking algorithm are used:
lexAccessLb -n -i:yes -o:yes.out
fgrep "|No Result Found-" yes.out |wc -l ... should be 0
lexAccessLb -n -i:no -o:no.out
fgrep "|No Result Found-" no.out |wc -l ... should be the same size as no.out
III. Process to get precision on new LMWs from candidate list
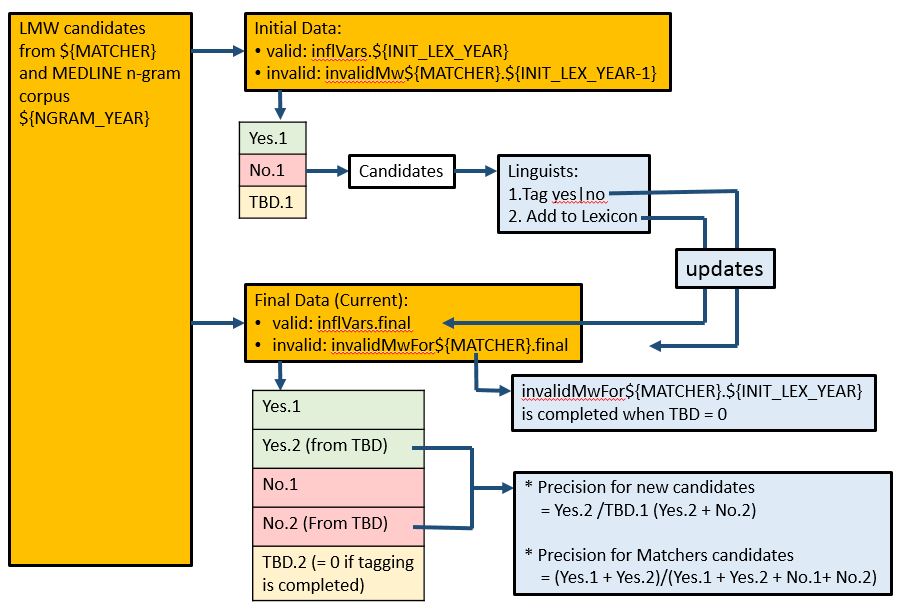
| Step | Description | ||
|---|---|---|---|
| 0 | Prepare valid and invalid files:
|