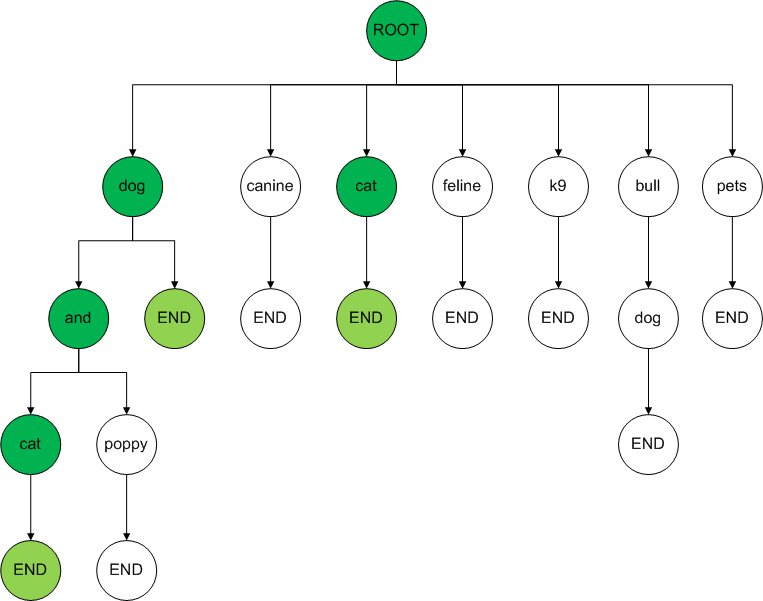
UMLS-Core: Sub-Term
| Terms |
|---|
| dog |
| canine |
| cat |
| feline |
| k9 |
| bull dog |
| dog and cat |
| pets |
| puppy and kitty |
| i | curTerm | branchMatches | matchTerms |
|---|---|---|---|
| 0 | who let dog and cat out | ||
| 1 | let dog and cat out | ||
| 2 | dog and cat out |
|
|
| 3 | and cat out |
| |
| 4 | cat out |
|
|
| 5 | out |
|
return matched terms | start index | end indexes: