Dual Embedding in the CBOW Model
1. Introduction
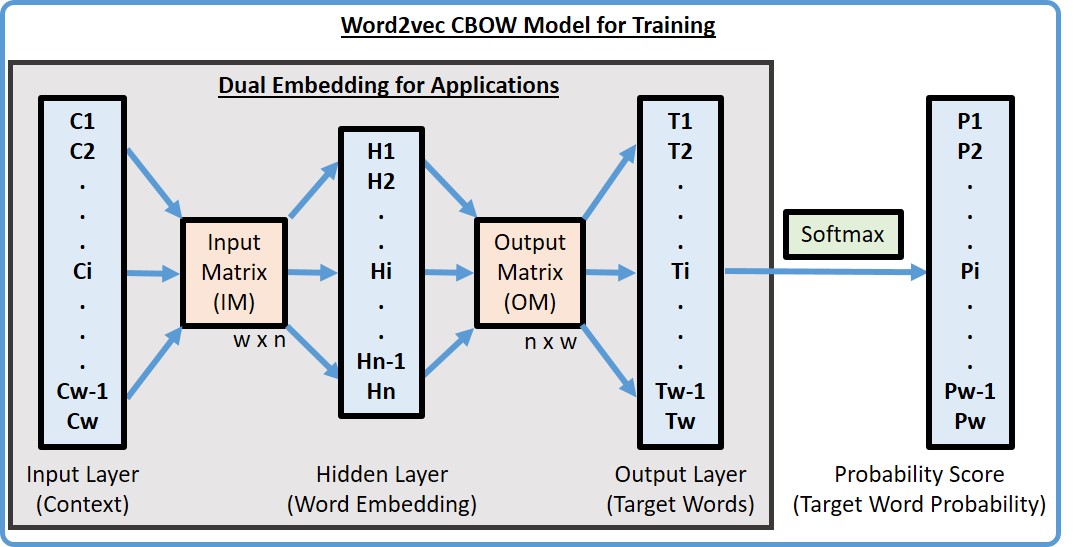
The word2vec CBOW model was used for context-dependent ranking due to its simplicity and outstanding performance. The CBOW is a shallow machine learning neural network model with a single hidden layer (see the figure below). It is used to predict a target word at the output layer from a given context in the input layer. Two matrices, the input matrix (IM) and output matrix (OM), are used to calculate the hidden layer ([H] 1xn = [C] 1xw x [IM] wxn) and target words ([T] 1xw = [H] 1xn x [OM] nxw), respectively, where: W is the total number of words in the corpus and N is the dimension of hidden layer. Finally, the softmax function is used to convert output layer to probabilities (Pw) for updating OM and IM through backpropagation during the training process. The IM is known as the word vector [22-23] and used solely in almost all word2vec applications while the OM is always disregarded. We applied both IM and OM matrices to compute context scores of the predicted target word with given contexts ([T] 1xw = [C] 1xw x [IM] wxn x [OM] nxw) in CSpell. Namely, treat the hidden layer and target words as the 1st and 2nd embedding, respectively. The softmax function was not used because backpropagation is not needed (after training) in the application. The consumer health corpus established for word frequency was used to train the CBOW model to generate IM and OM. We modified word2vec code to generate both the IM and OM using window size of 5 and embedding size of 200. Context scores might be positive, zero, or negative. A zero context score means the target word does not have a word vector, which was not chosen over a negative score.
2. Algorithm of CBOW Model
- Input layer: context (all words in the corpus)
=> 1-hot, 1 for words in context, 0 otherwise
- Hidden layer: condensed words (size of word vector)
=> [H]1xn = [C] 1xw [IM]wxn
- Output layer: predicted target word
=> [T]1xw = [H]1xn [OM]nxw
- Output probability score: use softmax to normalize output layer to 0.0 ~ 1.0
=> softmax: P(Ti|Tall) = exp(Ti)/Sum(Tk), where k = 1,...w
- Error function: [target vector] - [output probability]
- Learning: use backpropagation to update [OM] and [IM]
- Training: proceed with different context and target words
- [Input Matrix] (syn0) is the default output and used as word vectors in word2vec
- [Output Matrix] (syn1n) is not provided by word2vec, need to modify the source code to generate it.
3. Algorithm of Dual Embedding and Prediction Score
- Scoring:
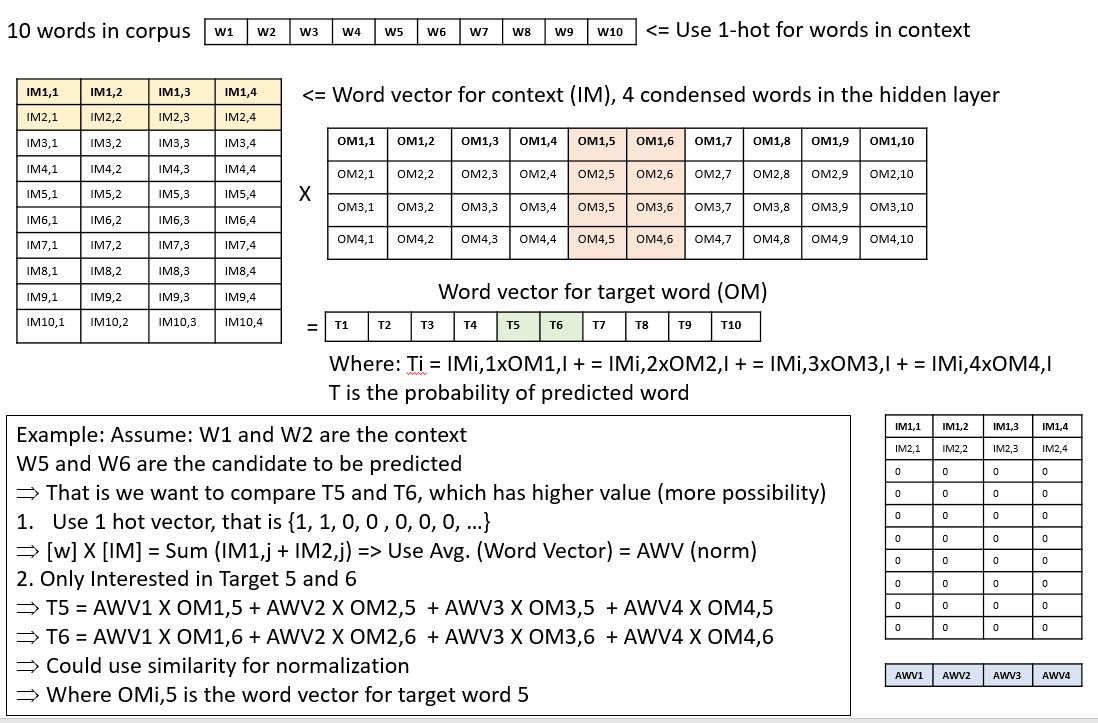
- Use dual (IM and OM) to calculate the context score, that is to feed the context back to the original model.
=> [IM]wxn x [OM] nXw = [Dual] wxw
=> [T] 1xw = [C] x [IM] x [OM] = [C] 1xw x [Dual] wxw
=> [C]: use 1-hot for the input context
=> [T]: only retrieve scores of candidates for prediction
- If only use IM for context and target words, that is to compare the similarity of word vectors (condensed word)? How similar of two words does not necessary a good way to predict the word from context.
- Context word vector: use average word vector from [Input Matrix] for all words in the context (Hidden layer)
- Target word vector: use average word vector from [Output Matrix] for all words in the candidate
- Use inner dot or cosine similarity (-1 ~ 1, for normalization) to get the context score
- Implementation Detail Example:
- Ranking:
- Positive: higher score means better rank
- 0: means the target words does not have word vector in [OM]. No information are available. Candidates with 0 score should not be applied this method because candidates with 0 score might have better or worse possibility (compare to negative score) to be the target words.
- Negative: higher score is higher rank only if all candidates have negative score
References: