CSpell Pipeline Design
I. Introduction
Different types of errors have different characteristics and require specific strategies for corrections. A multi-layer design consisting of models for non-dictionary-based and dictionary-based corrections was implemented in CSpell. CSpell integrates several stand-alone spelling correction models combined in the sequential order as shown in the following figure.
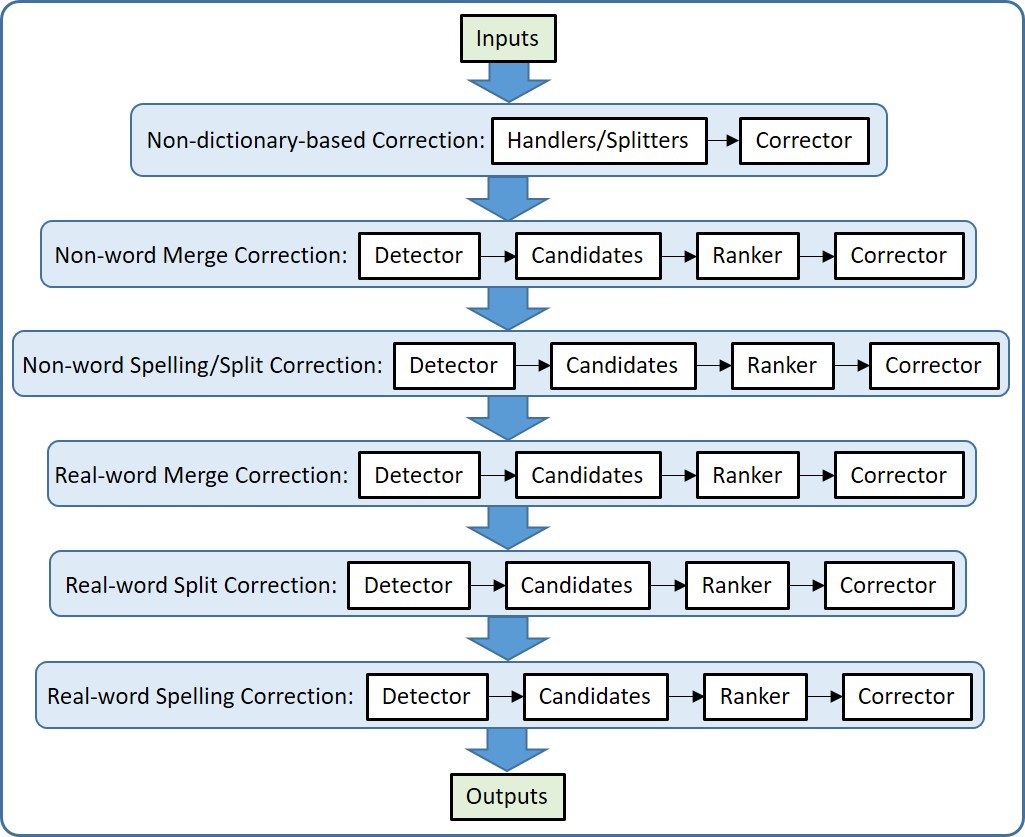
II. Non-dictionary-based correction
The non-dictionary correction model includes handlers and splitters.
Splitters uses the Lexicon to derive generic patterns for matchers and filters for split operation on run-on on digits and punctuation. These patterns are implemented in regular expression and algorithm for split operations and briefly shown in the following diagram.

They were arranged as a chain of intermediate operators to handle HTML/XML tags introduced by the software that consumers use to ask questions, informal expressions and missing spaces on adjacent punctuation or digits.
III. Dictionary-based correction
The dictionary-based correction model includes four modules:
